What is a client?
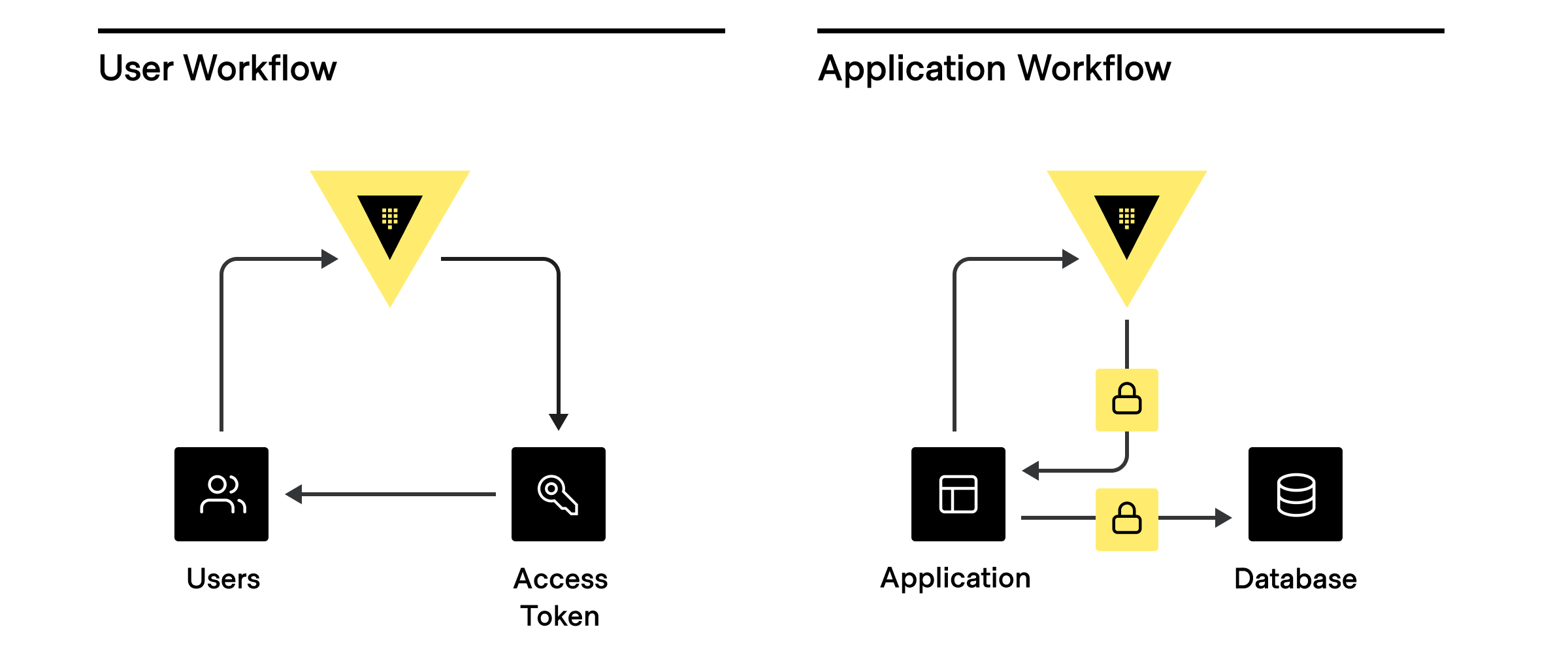
Before we dive into understanding the approach used to count the number of clients accessing Vault, we need to first understand what clients represent. Clients basically represent anything that has authenticated to Vault to do something. Users are people who log into the cluster to manage policies, set up dynamic secret rotation, and more. So every user that logs into the Vault is considered a client. Whereas every application, service, or any other machine-based system that authenticates to Vault is also considered a client.
There are three main ways clients are assigned an identity:
- External Identity Management Platform or SSO: Active Directory, LDAP, OIDC, JWT, GitHub, Username/password, etc.
- Platform or server-based identities: Kubernetes, AWS, GCP, Azure, PKI, Cloud Foundry, etc.
- Self Identity: AppRole, tokens (without an associated auth path or role)
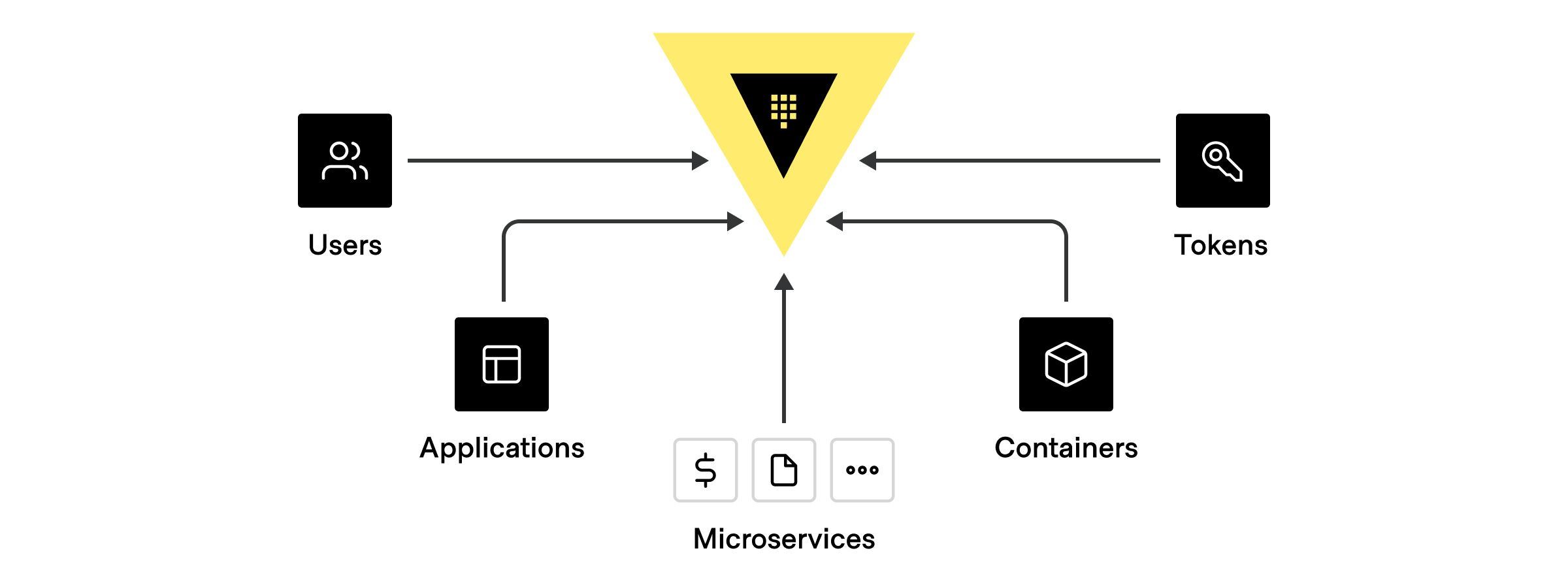
There can be many different types of clients that authenticate and communicate with Vault using one of the above identities, including:
- Human users: GitHub ID, username/password, LDAP, Active Directory, Kerberos, JWT/ OIDC claims, OKTA
- Applications or Microservices: 2-Factor Authentication methods such as AppRole, or by LDAP, Active Directory, or based on the platform’s identity, such as credentials from AWS, Azure, GCP, AliCloud, OCI, Kubernetes, Cloud Foundry, etc.
- Servers and Platforms: VMs, Containers, Pods (Identified by LDAP, Active Directory service accounts, AWS, Azure, GCP, AliCloud, OCI, Kubernetes, TLS Certs
- Orchestrators: Nomad, Terraform, Ansible, or Continuous Integration Continuous Delivery (CI/CD) Pipelines where each pipeline usually identified by 2FA
- Vault Agents: acting on behalf of a app/microservice, typically identified by App role, Cloud credentials, Kubernetes, TLS Certs
- Tokens: which are not tied to any identities at all. These should be used sparingly. Hashicorp recommends always associating tokens to an entity alias and token role.
How do clients work in Vault?
When anything authenticates to Vault, be it a user, application, machine, etc., it is associated with a unique entity within the Vault identity system. The name reported to the identity systems by the different types of authentication methods varies (list below), each entity is created or verified during authorization. There are scenarios where tokens can be created outside of the identity system, without an associated entity. In this scenario, these tokens are considered clients (for production usage, it should be rare to have any tokens created outside any identity systems).
But wait, there’s more...
Want to take full advantage of the Vault identity system and how clients are counted? The Vault identity system also has Entity Aliases and Identity Groups.
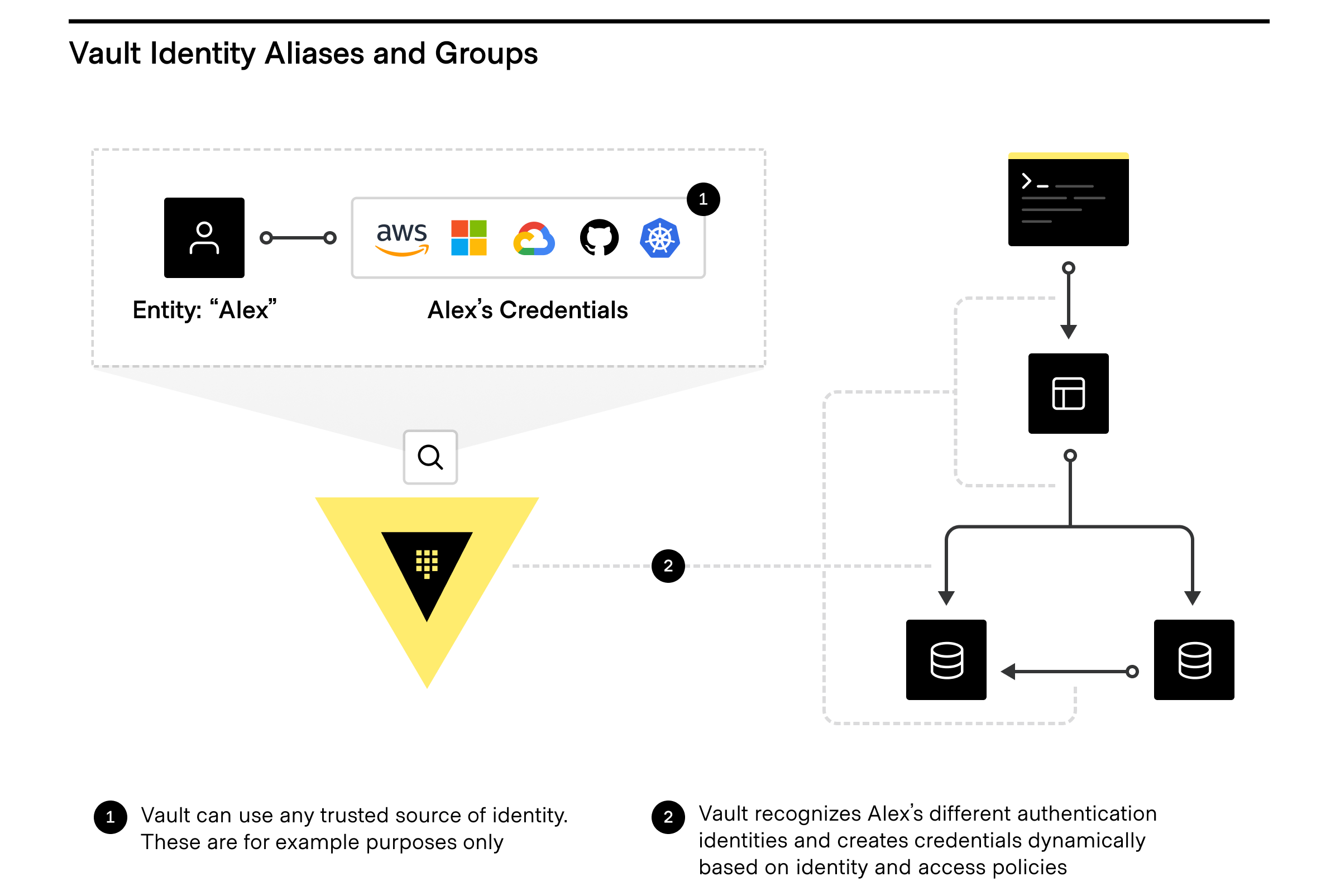
Entity aliases
Entity Aliases enable users or services to authenticate with more than one method and are associated with the same policy to share resources and count as unique entities.
Identity groups
Identity Groups within Vault leverage entities, in that Vault enables teams to create and manage logical groupings of entities. Identity Groups that can be based on organizations or teams within companies and can be used to assign policies and metadata, making user management dramatically simpler, especially for automating workflows by using Identity Groups to quickly and easily grant access to secrets and functionality within Vault.
For more on managing access with identity, entities, and more, check out Identity-based Security and Low-trust Networks and the HashiCorp Learn tutorial Identity: Entities and Groups | Vault
How does Vault avoid counting the same entity twice?
Using the identity system allows for Vault to make sure that entities aren’t counted more than once. Once you determine the identity and authentication method to be used for each, human, application, platform, and CI/CD pipeline, upon authentication for the first time in a billing period, Vault instantiates a unique entity. For example, say you have an application “AppX” that needs to get a secret from Vault using the AppRole method. Since AppX has an associated entity within Vault with associated policies, Vault knows every time that AppX is authenticating and authorizing, so AppX is only counted once.
Non-entity tokens
If you choose to use the Token Auth Method without an identity, this will create a non-entity token. Starting with Vault 1.9, any number of non-entity tokens having the same namespace and set of policies assigned, count as one client. In earlier versions, every non-entity token counted as a separate client, which could rapidly drive up client count to unrealistic values. If you are using Vault 1.8 or earlier, and need to address this without upgrading, one option is to create a Token Role first, with allowable entity aliases and create your token with the appropriate role and entity alias name. All tokens issued with the same entity alias name count as one client.
Differences between a direct entity and a non-entity token
While the definition of clients appears to be simple on the surface, there are many nuances involved in the computation of clients. As mentioned, clients are unique applications, services, and/or users that authenticate to a Vault cluster. When anything authenticates to Vault, it is associated with a unique identity entity within the Vault Identity system. The name reported to the identity systems by the different types of authentication methods varies, and each entity is created or verified during authorization.
One thing to note is that Vault clients are a combination of active identities as well as non-entity tokens. Identity entities are unique users, and when identities authenticate to Vault, corresponding tokens are generated. However, there are some situations in which tokens are generated without corresponding identities (e.g., when using the token auth method to create a token for someone else whose identity is unknown). As such, these non-entity tokens also represent users, and are counted towards the overall client aggregates. Here are some situations in which non-entity tokens get created within Vault.
- Tokens within Vault are the core method for authentication. You can use Tokens to authenticate directly, or use the auth methods to dynamically generate tokens based on external identities.
- There are scenarios where tokens are created outside of the identity system without an associated entity. For this reason, unique identity entities alone cannot always add up to the total unique authentications made to Vault over a stipulated time period.
- In a scenario where tokens are created outside of the identity system, these tokens are considered clients. Note that it should be rare for production usage to have any tokens created outside any identity systems.
- There are a few ways of creating tokens without entities: Token Roles, Token Create APIs, Wrapping Tokens, and Control Groups. For more information, refer to the What is a Client? documentation.
Considerations for namespaces
Since namespaces represent logical isolations within a single Vault cluster for administrative purposes, consideration must be made on how Vault clients are determined in this context.
- If a client authenticates to Vault in a parent or root namespaces, it is considered the same client in all child namespaces. This is obvious as it is within the same logical isolation.
- However if a client authenticates to Vault in two separate namespaces, because of logical isolation they are not considered as the same client. As an example,
/namespaceA/ldap/auth/login/bobis not related to/namespaceB/ldap/auth/login/bob. If the intent is that “Bob” is the same client, authenticate into two namespaces:- Move the auth to the parent workspace and any auth to child namespaces would be considered as the same client
- Place that auth in the root namespace to be considered as 1 client in all namespaces.
See also the guide Secure Multi-Tenancy with Namespaces | Vault.
Authentication methods and how they’re counted in Vault
Below is a list of supported authentication methods within Vault. You can also set up custom auth methods with secure plugins.
Each authentication method has a unique identifier to determine unique identity, similar to a driver license number, that uniquely determines an identity with a driver’s license.
How does this relate to Vault clients? As outlined above, and as an example, if you chose to identify a microservice by AppRole auth method, then assign a role id for that microservice. A role id is the microservice’s username and identity. You should not have different microservices use the same role id. Different microservices should use different role ids. However if microservices (or multiple VMs, or containers), are exact copies using the same role id, they will all have the same identity. This is the appropriate security posture to mitigate any risk, and an operator can easily approve or deny access to secrets for that one role id, without affecting other services. It is important as you choose an identity for each human, app, service, platform, server and pipeline, that you pay attention to the name below that makes each method unique and be given an identity.
| Auth method | Name reported by auth method |
|---|---|
| AliCloud | Principal ID |
| AppRole | Role ID |
| AWS IAM | Configurable via iam_alias to one of: Role ID (default), IAM unique ID, Full ARN |
| AWS EC2 | Configurable via ec2_alias to one of: Role ID (default), EC2 instance ID, AMI ID |
| Azure | Subject (from JWT claim) |
| Cloud Foundry | App ID |
| GitHub | User login name associated with token |
| Google Cloud | Configurable via iam_alias to one of: Role ID (default), Service account unique ID |
| JWT/OIDC | Configurable via user_claim to one of the presented claims (no default value) |
| Kerberos | Username |
| Kubernetes | Service account UID |
| LDAP | Username |
| OCI | Rolename |
| Okta | Username |
| RADIUS | Username |
| TLS Certificate | Subject CommonName |
| Token | entity_alias, if provided (Note: please ensure that entity_alias is always used) |
| Username/Password | Username |
Considerations with CI/CD
Orchestrators and Continuous Integration Continuous Delivery (CI/CD) Pipelines such as Nomad, Terraform, Ansible and the like, along with CI/CD tools such as Jenkins, Bamboo, Azure Devops, GitLab and GitHub Ops, and the like, can be used to authenticate to and request secrets from Vault during infrastructure or application/ service deployment. While the discussion below focuses on CI/CD, it is also applicable to orchestrators.
A CI/CD workflow can encompass many pipelines. Let us consider your options:
- Master CI/CD identity: Would the overall CI/CD orchestrator be given a master identity (e.g. app role, token with an entity alias), authenticate to Vault, and receive all secrets for all pipelines and all applications/infrastructure to be deployed?
- Pipeline Identity: Or would every CI/CD pipeline be given an identity (e.g. app role, token with an entity alias), authenticate to Vault once and retrieve all the secrets for each application/ infrastructure to be deployed??
- Pipeline and App/ Service/ Infra identity: Or would every CI/CD pipeline be given an identity (e.g. app role, token with an entity alias), authenticate to Vault once and then give each application/ service/ infrastructure deployed, workflow its own identity, which upon bootstrap, in turn, authenticates to Vault on its own to retrieve a secret?
From a threat model and security assessment perspective, option 3 above, where the pipeline does not have access to any secret, but allows applications, services or infrastructure to get its own secrets upon bootstrapping, is the most secure approach. With options 1 and 2, there is a risk that if someone gets access to your CI/CD workflow (option 1), or your pipelines (option 2), they would gain access to every or some of the secrets used by your apps and services. Using the principle of least privilege, where you only want to give access to secrets where necessary, there should be little or no gap between your secrets distribution and when it is accessed. Therefore one should avoid inadvertently giving your orchestrator and CI/CD tool god-like privileges where it potentially can access every secret for every app, service or infrastructure you deploy.
If someone goes wrong in option 1 and you revoke access, all pipelines are affected. If something goes wrong in option 2 and you revoke access to a pipeline, only that pipeline is affected, and you limit your security risk blast radius. If something goes wrong in option 3 you can just revoke an app or service without affecting everything else. Please carefully consider your security options as you manage security in a dynamic world.
From a Vault client perspective, option 1 is one client, the Master CI/CD identity; option 2 is one client for the Master CI/CD identity, and one client for each pipeline; option 3 is one client for the Master CI/CD identity, one client for each pipeline, and one for each app, service deployed.
Onboarding clients - putting it all together
The guide: “Onboarding Applications to Vault Using Terraform: A Practical Guide“ is an example on how to build an automated HashiCorp Vault onboarding system with Terraform to accommodate Vault client using naming standards, ACL policy templates, namespaces, pre-created application entities, and workflows driven by VCS and CI/CD.
Client count
The number of active clients using a Vault cluster is the total of:
- active entities: identity entities that create a token via a login
- active non-entity tokens: clients associated with tokens created via a method that is not associated with an entity
Prior to Vault 1.6, this metric could only be measured from the audit log, using the
vault-auditor tool. Starting with Vault 1.6, the number of clients per month, or for
a contiguous sequence of months, can be measured by Vault itself.
As of Vault 1.9, the total client count should always be measured using Vault itself. The metrics shown by the Vault UI are the source of truth for this data.
Please refer to Vault Usage Metrics for a step-by-step tutorial and description of how to use the UI.
Measuring clients
Each time a token is used, Vault checks to see whether it belongs to an identity entity that has already been active in the current month. New entities are added to a log in Vault storage periodically. Tokens without entities are tracked separately and added to the "non_entity_tokens" count. Please see the 'Tracking non-entity tokens' subsection below for a detailed explanation of how such tokens are tracked by Vault.
At the end of each month, Vault creates precomputed reports listing the number of active entities, per namespace, in each time period within a configurable retention period. This process deduplicates entities by ID, so that if an entity is active within every calendar month, it still only counts as one client for the entire year.
There are no client count metrics available until after the first calendar month finishes.
The client counts sum activity from all nodes in a cluster, including batch tokens created by performance standby nodes. Performance secondary clusters have their own client population, and their own client metrics; Vault does not aggregate or deduplicate clients across clusters. However, the logs and precomputed reports are included in DR replication.
Costs of measurement
Each active entity in the log consumes a few bytes of storage. Vault limits the number of identity entities it records per month (to 656,000) as a safety measure to prevent unbounded storage growth. However, typical storage costs should be much less. 1000 monthly active entities will require about 1.5 MiB of storage capacity over the default 24-month retention period. A smaller amount of additional storage is used for precomputed reports for all valid start/end pairs of months.
Disabling measurement
To avoid this potentially unwanted storage usage, the client count feature can be disabled via the UI or API. By default, the client count is disabled on open source builds, and enabled on Enterprise binaries. The CLI command to change its state is:
If you disable the client counter, then all complete months and all precomputed reports will remain in storage until their normal expiration time. This allows queries to be run on older data, even if no new data is being collected.
Vault does not report across a disable/enable cycle of the client count. All subsequent reports will start at the time that the feature is enabled.
Understanding non-entity tokens
A token without an entity can be created in any of the following ways:
- A root token creates a token via
auth/token/create. - Any other token without an entity creates a child token via
auth/token/createor a token role. - An orphan token is created via
auth/token/create-orphan; such a token does not inherit the entity of its creator. - A token is created using a token role that specifies
orphan=true. - An auth method would normally create an entity, but is not allowed to do so, such as:
- A batch token is created on a performance standby node.
- A service token is created on a performance secondary replica, using a local mount.
The entity_id field will be empty, or show as n/a, for any token that is classified as a non-entity token:
To reduce the number of non-entity tokens in use, consider switching to an authentication method such as AppRole instead of handing out directly-created tokens. Ensure that entities and entity aliases exist for all login methods used to create batch tokens.
Tracking non-entity tokens
As of Vault 1.9, non-entity tokens are tracked as unique clients based on the policies the token has access to and the namespace in which it was created. Non-entity tokens that are assigned the same set of policies and are created in the same namespace will be tracked as the same client. Conversely, if two non-entity tokens have a different policy set or are created in different namespaces, they will be tracked as two separate clients.
Please note that before the release of Vault 1.9, non-entity tokens were each tracked separately. That is to say, two non-entity tokens would always be counted as two separate clients.
Auditing clients
As of Vault 1.9, the Vault Audit Log contains a client_id field in the request. The client_id field
contains an Entity ID for requests that are made with tokens with entities, or a unique client ID for
non-entity tokens.
Consumers of the audit log will be able to distinguish between these two types of client IDs by comparing
the value in the client_id with the value of the entity_id in the Auth section of the response. If
the two values are the same, then the client_id is an entity_id. If not, then the client_id was
generated from the use of a non-entity token.
An empty client_id field in a request means that Vault did not track a client for that
request; this can happen if the request is unauthenticated, or made with a root token or wrapped token.
API and permissions
Please see Client Count API for more details. Note that this API is marked as "internal" so its behavior or format may change without warning. The UI is the preferred means of interacting with the client count feature.
For the UI to be able to use the client count feature, it needs read permission to the following paths:
For the UI to be able to modify the configuration settings, it additionally needs update permission to
sys/internal/counters/config.